Introduction to Apache Kafka: A Powerful Distributed Streaming Platform

Businesses must be able to analyse and analyse massive amounts of data in real time in today's fast-paced, data-driven environment. At this point, Apache Kafka comes into play. You may publish, subscribe to, store, and process real-time records streams using Apache Kafka, a highly scalable and fault-tolerant distributed streaming platform. Its ability to manage high-throughput, low-latency, and fault-tolerant data streams has helped it gain popularity.
Understanding the Architecture of Kafka:
- The three main parts of the distributed architecture on which Kafka is based are producers, brokers, and consumers. Data records are published to Kafka topics by producers. Small data units like log messages, system events, or sensor readings are frequently included in these recordings. Producers can split data for efficient storage and processing and write data to specific themes.
- Brokers: The foundation of Kafka's design is made up of brokers. They are the key element in charge of storing and transferring data between producers and consumers. One or more partitions of each topic are handled by one or more brokers in a Kafka cluster. It guarantees fault tolerance by replicating partitions over many brokers.
- Consumers: In real time, consumers read and process data from Kafka topics. They can choose to subscribe to one or more themes and read content at their own leisure. Customers can control their own data consumption by maintaining their own offset in Kafka.
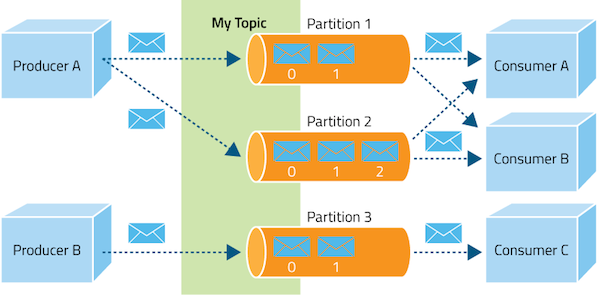
Apache Kafka's main features are as follows:
- Scalability: By adding more brokers to the cluster, Kafka may be scaled horizontally to accommodate massive amounts of data. As a result, it is a great option for applications that require big data analytics and processing.
- Fault Tolerance: Kafka provides fault tolerance by replicating data over several brokers. When one broker falters, another steps in to take over, guaranteeing that data is always available.
- High Performance: Kafka is renowned for its outstanding performance. It is perfect for real-time streaming applications since it has minimal latency and can process thousands of messages per second..
- Durability: Kafka allows you to store enormous volumes of data over time because it stores data on disc. Even when users aren't actively using the data, its longevity ensures that it won't be lost.
- Stream Processing: Popular stream processing frameworks like Apache Storm, Apache Flink, and Apache Samza all operate well with Kafka. Real-time streaming data processing and analytics are made possible by this.
Apache Kafka Use Cases:
- Log Aggregation: Kafka is a fantastic option for collecting and aggregating logs from various sources because of its high throughput and durability. It gives you the ability to handle log-based data effectively, centralise logs, and do real-time analytics.
- Messaging Systems: As a reliable messaging system, Kafka can be used to decouple various parts of a distributed application. It makes ensuring that messages are conveyed consistently and in the order that they were written.
- Real-time Data Pipelines: Real-time data pipelines can be created with Kafka, enabling the integration of several systems and applications. It makes it possible for data to move easily across several processing layers.
- Event Sourcing: A pattern called event sourcing records state changes in an application as a series of events. Kafka is a great choice for implementing event sourcing because it allows you to maintain an exhaustive history of events thanks to its append-only log structure.
Note:-Before getting into the code, we should review some basic concepts. In Kafka, each topic is divided into a set of logs known as partitions. Producers write to the tail of these logs and consumers read the logs at their own pace. Kafka scales topic consumption by distributing partitions among a consumer group, which is a set of consumers sharing a common group identifier. The diagram below shows a single topic with three partitions and a consumer group with two members. Each partition in the topic is assigned to exactly one member in the group.
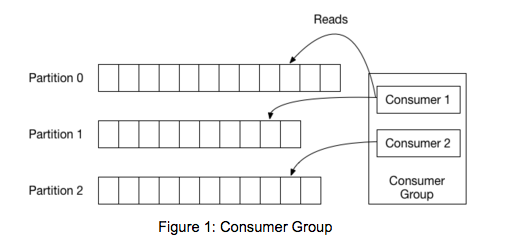
While the old consumer depended on Zookeeper for group management, the new consumer uses a group coordination protocol built into Kafka itself. For each group, one of the brokers is selected as the group coordinator. The coordinator is responsible for managing the state of the group. Its main job is to mediate partition assignment when new members arrive, old members depart, and when topic metadata changes. The act of reassigning partitions is known as rebalancing the group.
When a group is first initialized, the consumers typically begin reading from either the earliest or latest offset in each partition. The messages in each partition log are then read sequentially. As the consumer makes progress, it commits the offsets of messages it has successfully processed. For example, in the figure below, the consumer’s position is at offset 6 and its last committed offset is at offset 1.
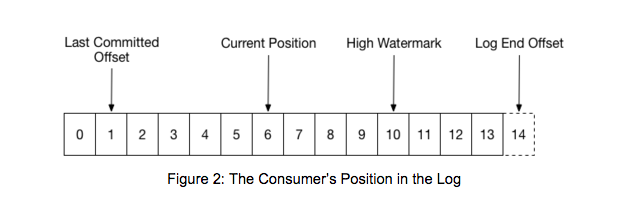
When a partition gets reassigned to another consumer in the group, the initial position is set to the last committed offset. If the consumer in the example above suddenly crashed, then the group member taking over the partition would begin consumption from offset 1. In that case, it would have to reprocess the messages up to the crashed consumer’s position of 6.
The diagram also shows two other significant positions in the log. The log end offset is the offset of the last message written to the log. The high watermark is the offset of the last message that was successfully copied to all of the log’s replicas. From the perspective of the consumer, the main thing to know is that you can only read up to the high watermark. This prevents the consumer from reading unreplicated data which could later be lost.
Conclusion:
The manner that companies manage and analyse data in real-time has changed as a result of Apache Kafka's emergence as a potent distributed streaming platform. It is appropriate for a variety of use cases, including log aggregation, messaging systems, real-time data pipelines, and event sources, thanks to its scalability, fault tolerance, and high performance.